
- 01-04-25BIT as a Service
- 26-03-25Internetproviders verliezen rechtszaak over blokkeren websites
- 19-02-25BIT introduceert server-side e-mailfiltering met Sieve
- 06-02-25Shared hosting wordt opgefrist
- 28-11-24ECOFED uitgeroepen tot publieksfavoriet bij Computable Awards
- 21-11-24Een goede cloud heeft een kundige dirigent nodig
- 17-10-24ECOFED wint ICT Innovatieprijs Regio Foodvalley 2024
- 01-08-24BIT geeft kaarten weg voor F1 in Zandvoort
- 24-04-24Status.bit.nl in nieuw jasje!
- 12-04-24Nieuw bij BIT: GPU hosting
Netwerkstatistieken in de BIT Portal: technieken en tools
01-07-2020 11:22:45

Het is al jaren voor klanten van BIT mogelijk om inzicht te krijgen in het bandbreedteverbruik van hun internetverbinding op locatie of in één van de datacenters van BIT. Tot voor kort werden deze statistieken aangeboden via een aparte URL, maar inmiddels zijn deze statistieken beschikbaar gekomen in de BIT Portal. Door nieuwe tools en technieken toe te passen zijn we nu beter in staat aan klanten te tonen wat er op hun verbinding gebeurt.
We kunnen nu meer metingen aan klanten laten zien, en de metingen die er zijn kunnen we tonen in een hogere resolutie. Dit maakt het voor klanten mogelijk om sneller en beter eventuele problemen op hun netwerk te detecteren en analyseren.
In deze blogpost ga ik dieper in op de technieken en tools die we gebruikt hebben om deze functionaliteit aan onze klanten te kunnen bieden.
Streaming telemetry
Veel ‘traditionele’ tools die gebruikt worden om bandbreedtemetingen te doen, waaronder MRTG, RRDtool, Cacti en Observium, verzamelen standaard één meting per vijf minuten. Om écht een goed beeld te krijgen van wat er in een netwerk gebeurt, is dit vaak onvoldoende. Vooral verkeerspieken die korter duren worden niet meer opgemerkt omdat er uitgemiddeld en daarmee afgevlakt wordt.
Dergelijke pieken kunnen echter wél een grote invloed hebben op de beschikbaarheid van diensten in de netwerken van onze klanten. Een verbinding die één van de vijf minuten volledig belast wordt en daarna vier minuten niet, zal een gemiddelde belasting per vijf minuten tonen die geen indicatie van problemen toont, terwijl die er wel degelijk zijn.
Met de bouw van ons nieuwe colocatienetwerk, wat in 2018 in productie genomen is, ontstonden er mogelijkheden om dit anders aan te pakken.
Waar de meeste tools periodiek (vaak dus eens per vijf minuten) via SNMP meetwaarden binnenhalen, maken we op onze Arista switches gebruik van streaming telemetry. Bij streaming telemetry verstuurt de netwerkapparatuur meetdata op het moment dat meetwaarden veranderen in plaats van te wachten tot de apparatuur (vaak minuten later) weer bevraagd wordt. Het gevolg hiervan is dat er (vrijwel) real-time statistieken ontstaan.
Wat tevens een gevolg hiervan is, is dat het aantal meetwaarden per tijdsperiode niet meer vast bepaald worden door het interval waarmee de apparatuur bevraagd wordt, maar volledig afhankelijk is van hoe snel meters veranderen.
Data-opslag
Een gevolg van het gebruik van streaming telemetry is dat er veel meer data verzameld wordt, want een actieve switchpoort produceert continu nieuwe metingen. De ‘klassieke’ tools gebruiken vaak RRDtool onder de motorkap om metingen op te slaan, of anders een database als bijvoorbeeld MySQL of Postgres. Het grote nadeel aan deze wijze van opslaan is dat deze zich niet zo goed leent voor de grote hoeveelheden meetpunten die we verzamelen en de operaties (groeperen, filteren, berekeningen) die we daarop willen toepassen.
Gelukkig zijn er ook een nieuwere typen databasesystemen die zich wel erg goed lenen voor dit soort data. Deze databases zijn time series databases. Een time series database is een specifiek soort database dat ontworpen is om zeer grote hoeveelheden meetpunten die voorzien zijn van timestamp (een datum en tijd, vaak met hoge precisie) op te slaan, te verwerken en weer aan te bieden. Een van de bekendste implementaties is de open source tool InfluxDB, die ook bij BIT gebruikt wordt voor de opslag van metingen van netwerkapparatuur. Naast een tijdstip en een waarde biedt InfluxDB de mogelijkheid om één of meer labels aan een meting te hangen. Dat is in ons geval de naam van de switch en de switchpoort waar de meting bij hoort.
Dataverwerking
Maar daarmee zijn we er nog niet natuurlijk. Om metingen in de klantenportal van BIT te tonen in grafieken moeten er nog wel een aantal stappen gemaakt worden.
Onze Arista switches publiceren metingen via de OpenConfig gRPC standaard naar een server waarop een subscriber tool draait. Deze tool verzamelt de metingen en schrijft de voor ons relevante metingen weg naar een InfluxDB server.
Hiermee ontstaat een database die gevuld wordt met metingen voor alle switchpoorten in het datacenter van BIT. Daarmee zijn we er echter nog niet helemaal om zaken in de portal te tonen. Uiteraard hoort een klant metingen van al zijn eigen poorten, maar zeker geen metingen van andere klanten in te kunnen zien. Daarnaast hebben we te maken met klanten die wel eens verhuizen van de ene poort naar een andere poort, en met poorten die eerst van de ene klant zijn en op een later moment van een andere.
Om met al deze zaken rekening te houden maken we gebruik van een andere tool van de makers van InfluxDB met de naam ‘Kapacitor’. Kapacitor is gebouwd om snel data in InfluxDB databases te manipuleren via scripts. Bij BIT gebruiken we Kapacitor om data uit onze centrale InfluxDB database te exporteren naar klantspecifieke databases. De scripts die bepalen hoe er gesorteerd wordt, worden geautomatiseerd opgebouwd aan de hand van de configuratiedatabase die gebruikt wordt voor het configureren van klantpoorten.
Zodra een poort toegevoegd is aan de configuratiedatabase, wordt er data in de bijbehorende klantdatabase opgeslagen en als een poort uit de configuratiedatabase is verwijderd, wordt de ‘sorteerregel’ voor de betreffende klant aangemaakt, aangepast of opgeruimd.
Op deze manier ontstaat er een verzameling aan databases waarin vele miljoenen meetpunten opgeslagen worden. Om de groei in opslag en daarmee de tijd die het kost om de data er weer uit te halen te beperken, maken we gebruik van downsampling. Dit is een techniek die ook al gebruikt wordt in bijvoorbeeld RRDtool, waarbij je minder meetpunten bewaart naar mate data ouder wordt. Waarbij we van iedere poort op iedere switch van de laatste maand maximaal één meting per tien seconden bewaren, bewaren we daarnaast voor vierhonderd dagen lang één meting per vijf minuten. Dit downsampling kan direct in InfluxDB via continuous queries, maar aangezien wij toch al gebruikmaken van Kapacitor scripts wordt daarin ook de downsampling uitgevoerd.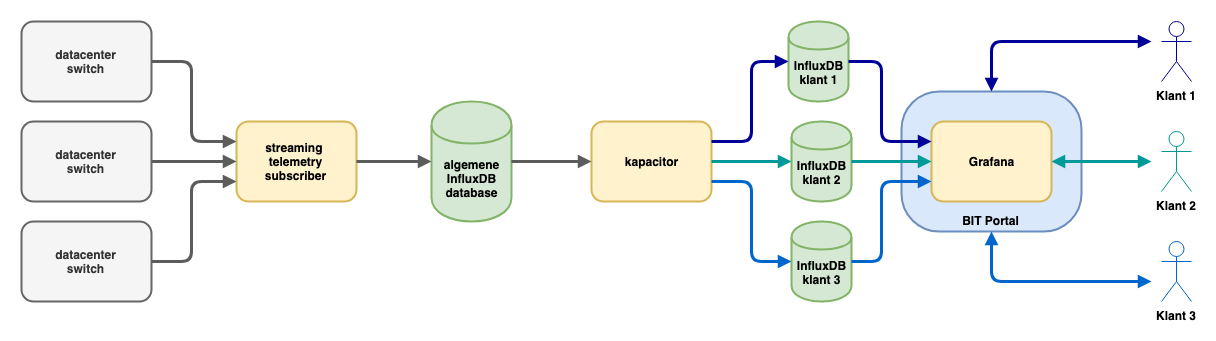
Visualisatie
Met InfluxDB is het dus mogelijk om een grote hoeveelheid meetpunten efficiënt op te slaan en weer terug te vinden, maar daarmee heb je nog geen mooie grafieken. Gelukkig zijn er inmiddels open source tools beschikbaar die mooiere grafieken kunnen maken dan oude tools als MRTG en RRDtool. Eén ervan is Chronograf, ook weer onderdeel van de InfluxDB suite, maar bij BIT hebben we ervoor gekozen om gebruik te maken van Grafana. Grafana kan met weinig moeite mooie dashboards met grafieken produceren op basis van data uit diverse soorten databases, waaronder ook InfluxDB. Grafana werd al gebruikt bij BIT om interne metingen te visualiseren, dus deze tool ook gebruiken voor visualisatie van grafieken voor klanten in de BIT portal was een logisch vervolg.
Een bijkomend voordeel hierbij is dat Grafana een groot scala aan soorten grafieken ondersteunt, waardoor we beter in staat zijn een visualisatiewijze te kiezen die het meest aansluit bij de informatie waar de klant naar op zoek is. Zo biedt Grafana bijvoorbeeld interactieve grafieken, waarbij ingezoomd kan worden op een interessant deel van de grafiek, en kunnen grafieken automatisch bijgewerkt om de paar seconden, zodat altijd de meest recente metingen getoond worden.
Wel moesten er een aantal dingen geregeld worden om Grafana te integreren in de portal. We wilden niet dat een klant die al ingelogd was in de portal, opnieuw zou moeten inloggen om grafieken te kunnen bekijken. Daarvoor biedt Grafana gelukkig goede oplossingen middels het invoegen van HTTP headers.
Het tweede aandachtspunt was veiligheid. We willen uiteraard niet dat klant A ooit bij de grafieken van klant B kan komen. Daarom maken we binnen Grafana gebruik van organisaties. Voor iedere klant wordt een aparte organisatie aangemaakt. Grafana datasources (de koppelingen met een InfluxDB database) en dashboards zijn allemaal uniek per organisatie. Het rechtenmodel van Grafana zorgt ervoor dat klanten alleen toegang hebben tot hun eigen dashboards en datasources.
Het derde grote aandachtspunt was het beheer van dashboards. Met het grote aantal organisaties, dashboards en grafieken is een geautomatiseerd systeem om dit alles aan te maken, bij te werken en verwijderen noodzakelijk.
Daarom hebben we tooling gebouwd die op basis van onze provisioning database (waarin staat welke switchpoorten bij welke klanten horen) automatisch dashboardconfiguraties kan produceren. Hiervoor wordt gebruik gemaakt van templates, waarin alleen nog de klantspecifieke zaken (de datasource, naam van de switch en het poortnummer) ingevuld moeten worden om een bruikbare configuratie te genereren. Dashboards worden automatisch gegenereerd en uitgerold naar de Grafana servers als er wijzigingen plaatsvinden in de provisioning database, aan de templates of als er nieuwe templates toegevoegd worden.
Grafiek één meting per vijf minuten
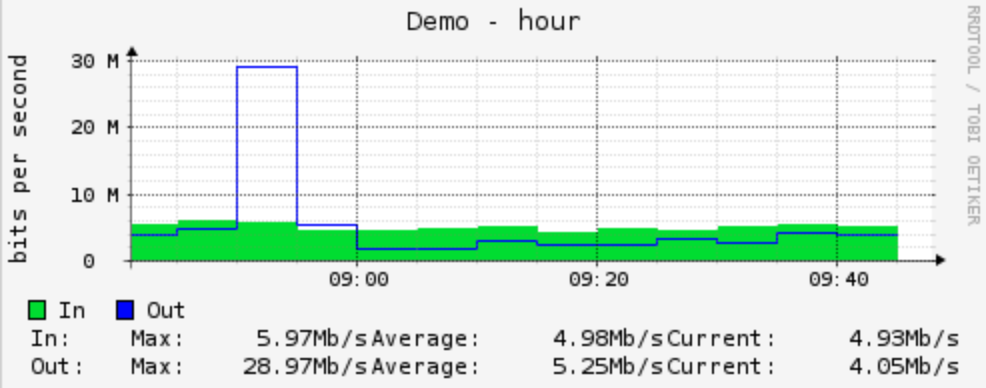
Grafiek met één meting per tien seconden

Deze twee grafieken tonen het verbruik van dezelfde switchpoort. Op de grafiek op basis één meting per vijf minuten lijkt de piek langer te duren maar lager te zijn, terwijl de grafiek met één meting per tien
seconden toont dat de grafiek eigenlijk kort, maar veel hoger was. Uit de grafiek van de errors op de poort blijkt vervolgens dat deze piek tot output discards leidde, een indicatie dat uitgaande poort onvoldoende capaciteit had om de piek op te vangen.
Nieuwe informatie
Door gebruik te maken van deze hele toolchain zijn we nu in staat om sneller nieuwe informatie in de portal beschikbaar te maken. Zo maken we nu al inzichtelijk hoeveel interface errors en discards we meten op switchpoorten. Het plan is om hier op korte termijn ook historisch inzicht in de link status aan toe te voegen.
Dergelijke informatie, waarvan we ook weer véél meetpunten verzamelen, maakt het voor klanten nog eenvoudiger om problemen met hun verbinding te detecteren en verder te analyseren. Een piek in het dataverkeer van BIT naar de klant, gecombineerd met output discards kan bijvoorbeeld een goede indicatie zijn dat er te weinig capaciteit is om bursts op te vangen, en een switchpoort die af en toe kortstondig z’n verbinding verbreekt wordt misschien niet opgemerkt door een monitoringsysteem wat slechts periodiek de status controleert, maar kan wel tot mindere beschikbaarheid van het achterliggende netwerk leiden.
Ook zijn we van plan om andersoortige data via dit systeem te ontsluiten. We zijn op dit moment bezig om te testen hoe we informatie over onze loadbalancing dienst kunnen visualiseren, en ook verwachten we dit jaar inzicht in virtuele servers te kunnen geven.
Mochten er vanuit klanten verzoeken over bepaalde metingen of de wijze van weergeven komen, dan zijn we hiermee in staat om er snel gehoor aan te geven.
Zelf aan de slag?
Streaming telemetry en ook meten met zeer korte intervallen in algemenere zin kan veel meer inzichten bieden over wat er gebeurt op een netwerk. Als je netwerkapparatuur het ondersteunt (en diverse merken netwerkapparatuur doen dat inmiddels) is dat zeker de moeite waard.
Ook voor inzicht in servers zijn inmiddels goede tools beschikbaar om metingen te verzamelen: de makers van InfluxDB bieden Telegraf aan; een agent die metingen naar InfluxDB kan publiceren. Een alternatief is Prometheus. Ondersteuning voor steeds meer soorten hard- en software komt beschikbaar voor beide tools, waardoor deze een centrale plek kunnen krijgen in het verzamelen van meetdata.
En zelfs als je nog niet met een hogere frequentie metingen kunt verzamelen, kan de combinatie van InfluxDB met Grafana voordelen bieden. De mogelijkheid om snel en eventueel geautomatiseerd dashboards te maken die aansluiten bij je informatiebehoefte kan ook dan tot nieuwe en betere inzichten leiden.
Door: Teun Vink