
- 01-04-25BIT as a Service
- 26-03-25Internetproviders verliezen rechtszaak over blokkeren websites
- 19-02-25BIT introduceert server-side e-mailfiltering met Sieve
- 06-02-25Shared hosting wordt opgefrist
- 28-11-24ECOFED uitgeroepen tot publieksfavoriet bij Computable Awards
- 21-11-24Een goede cloud heeft een kundige dirigent nodig
- 17-10-24ECOFED wint ICT Innovatieprijs Regio Foodvalley 2024
- 01-08-24BIT geeft kaarten weg voor F1 in Zandvoort
- 24-04-24Status.bit.nl in nieuw jasje!
- 12-04-24Nieuw bij BIT: GPU hosting
Deep Dive in het colocatienetwerk van BIT
02-10-2020 13:45:52

In een vorige blog heb ik verteld hoe we bij BIT bezig zijn om het volledige colocatienetwerk te vervangen door een nieuwe set-up, gebaseerd op apparatuur van Arista Networks. In deze blogpost zal ik verder in detail gaan over de techniek die achter deze set-up zit. Er is namelijk nogal wat veranderd ten opzichte van het oude netwerk.
Topologie van het oude netwerk
Het oude netwerk is vele jaren geleden ontworpen op basis van principes en technieken die toen actueel waren; een core/aggregatie/access model wat gebruikmaakt van het Spanning Tree Protocol (STP). In de loop der jaren is het netwerk wel regelmatig uitgebreid en vernieuwd, maar qua ontwerp is er in die tijd niet veel veranderd.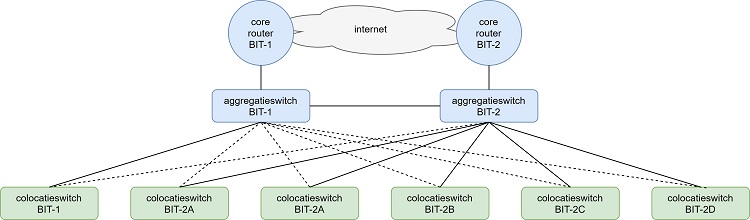
In het bovenstaande diagram staat het oude access netwerk schematisch weergegeven. Zoals daar te zien is, zijn er twee core routers die het netwerk ontsluiten via twee aggregatieswitches. Aan deze aggregatieswitches zijn de colocatieswitches gekoppeld. Iedere serverruimte heeft één of twee switches om apparatuur van klanten en BIT zelf op aan te sluiten, en ieder van deze switches is uit redundantie-oogpunt met beide aggregatieswitches verbonden.
Tussen de aggregatieswitches en de colocatieswitches wordt het spanning tree protocol gesproken om er voor te zorgen dat het netwerk loop-vrij blijft. Het is namelijk niet gewenst dat als er ethernetframes gegenereerd worden met een onbekende bestemming, deze oneindig door het netwerk 'geflood' worden. Een netwerk moet in de switching-laag loop-vrij zijn. Het spanning tree protocol zorgt daarvoor.
Er kleven echter best wat nadelen aan spanning tree implementaties:
- De snelheid waarmee verkeer omgeleid wordt als er veranderingen aan de netwerktopologie plaatsvinden, bijvoorbeeld doordat een verbinding uitvalt, is relatief laag. Dat betekent dat in zulke situaties er merkbaar overlast voor klanten kan ontstaan.
- Een topologie op basis van spanning tree is kwetsbaar Bij een te hoge CPU load op een van de switches of bij overbelasting van één van de verbindingen kan er juist een loop ontstaan in het netwerk, omdat een switch dan niet snel genoeg kan controleren dat de loop aanwezig is en daarom een geblokkeerde poort juist opent.
- Om klanten redundant aan te sluiten moet de apparatuur spanning tree meepraten met de spanning tree topologie van BIT. Dit betekent veel afstemming qua configuratie en een groter risico op problemen.
Topologie van het nieuwe netwerk
Het nieuwe access netwerk is gebaseerd op het zogenaamde spine-/leaf model, soms ook wel het Clos model genoemd. De topologie lijkt op het eerste oog veel op de dubbele sterconstructie die in het oude netwerk gebruikt werd.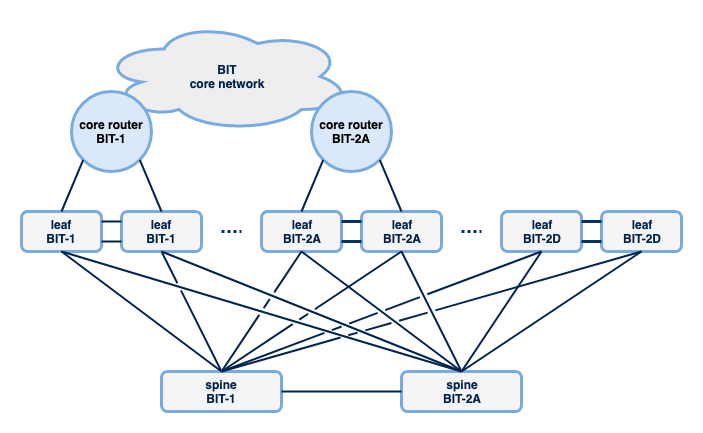
Bij het spine-/leaf model is er een groot aantal leaf switches die gebruikt worden om apparatuur op aan te sluiten. Voor BIT betekent dit dat er per serverruimte een aantal van deze leafs geplaatst is. Variërend van twee tot (op dit moment) acht leafs, afhankelijk van het benodigde aantal switchpoorten om klanten en apparatuur van BIT op aan te sluiten. Om verkeer tussen deze leaf switches mogelijk te maken worden spine switches gebruikt. In ons netwerk betreft het twee spine switches, geplaatst in BIT-1 en BIT-2A. Hierdoor ontstaat er een dubbele sterstructuur waardoor switches elkaar kunnen bereiken via maximaal één andere switch, te weten een spine switch. Iedere switch heeft vier verbindingen om verkeer naar andere delen van het netwerk te transporteren. Zoals in de eerdere blogpost al is laten zien, zijn deze verbindingen redundant en vindt overschakeling naar andere paden bij uitval razendsnel plaats, omdat er gebruik gemaakt wordt van andere protocollen om paden te kiezen tussen de switches. Hierover vertel ik later nog wat meer.
Spine-/leaf set-ups zijn niet noodzakelijk beperkt tot twee spines. Het kan dus zijn dat bij groei van ons netwerk uiteindelijk een derde en mogelijk een vierde spine geïntroduceerd worden. In dat geval hoeft iedere leaf switch slechts aan twee spines aangesloten te worden, en kun je dus blijven groeien zonder dat je spine switches nodig hebt die genoeg switchpoorten beschikbaar hebben om iedere leaf in het netwerk aan te sluiten.
De aansluitingen met de core routers (en daarmee de verbindingen naar het internet) worden op verschillende leaf switches geplaatst. Hierin verschilt de topologie dus van de oude topologie, waarbij de aggregatieswitches zowel het verkeer tussen de access switches als naar de core routers transporteren. Vergeleken met het oude netwerkmodel zijn er ook meer verbindingen met de core routers. Het voordeel hiervan is dat er meer capaciteit en meer redundantie is.
Als je de verbindingen met je core netwerk op de switches aansluit die het vele verkeer verwerken, kun je de hoeveelheid verkeer dat binnen je access netwerk transporteert beperken. In het traditionele model wat in het oude netwerk gebruik werd, moeten de aggregatieswitches voldoende capaciteit hebben om al het verkeer van het hele access netwerk te kunnen transporteren naar de core routers. Er ontstaat dus een soort trechtereffect, waarbij je steeds meer capaciteit nodig hebt op je aggregatieswitches op het moment dat je access netwerk groeit.
Routeren in plaats van switchen
Het nieuwe design is opgebouwd volgens het uitgangspunt dat we verkeer willen routeren, niet switchen. Het nadeel aan switchen is dat er loop protectie nodig is, zoals bijvoorbeeld met het eerder beschreven spanning tree protocol gedaan wordt. Daarom maken we gebruik van VXLAN. Dit is een techniek waarbij ethernetframes ingepakt worden in UDP datagrammen. Deze datagrammen worden vervolgens gerouteerd naar de juiste bestemming binnen het netwerk, waar ze weer uitgepakt worden en daarmee het oorspronkelijke ethernet frame op de bestemming uitkomt. Simpel gezegd routeren we dus ethernet door IP-tunnels. Het gevolg hiervan is dat ons netwerk volledig transparant is voor layer 2 protocollen als spanning tree, CDP en LLDP. Klanten kunnen al deze protocollen dus gewoon gebruiken door het BIT-netwerk heen. Ze worden door onze apparatuur getransporteerd en verder genegeerd.
Iedere switch heeft meerdere, in ons geval meestal vier, routes naar bestemmingen in het netwerk (en het internet) in zijn routetabel staan. Deze routes zijn allemaal gelijkwaardig en dankzij ECMP (Equal Cost Multi Path) routing kunnen ze ook allemaal tegelijk gebruikt worden. Als een verbinding wegvalt worden de routes via deze verbinding uit de routetabel verwijderd en zal het verkeer één van de overgebleven routes volgen.
Met VXLAN los je dus het probleem op dat je je netwerk loopvrij moet houden. Alleen ontstaat er een nieuwe uitdaging: je moet nog steeds wel weten naar welke switch het ingepakte ethernetframe gerouteerd moet worden. En dat kunnen ook poorten op meerdere switches zijn, want bijvoorbeeld bij broadcasts en unknown unicastverkeer moet het frame doorgestuurd worden naar alle andere switchpoorten die in hetzelfde VLAN geconfigureerd zijn. Er is dus een vorm van informatie-uitwisseling nodig om bij te houden welk MAC-adres en IP-adres op welke switch aanwezig is. Dit kan bijvoorbeeld door statische configuraties, maar in een netwerk zoals dat van BIT is dit ondoenlijk. De lijst wordt te groot en is veel te veranderlijk met alle klanten die apparatuur aansluiten en vervangen.
Daarom zijn er ook andere manieren om deze informatie uit te wisselen. Bij BIT gebruiken we hiervoor EVPN. EVPN is een extensie op het BGP routeringsprotocol die het mogelijk maakt om informatie over MAC-adressen en IP-adressen uit te wisselen. Het voordeel van BGP is dat het een dynamisch protocol is wat goed kan schalen. Daarnaast is het een open standaard, bestaat het protocol al lang en is het bekend bij netwerk engineers. Dit maakt het betrouwbaarder en makkelijker te implementeren.
Als er een nieuw apparaat aangesloten wordt of als een virtual machine verhuist naar een andere hypervisor, dan wordt de aanwezigheid van het MAC-adres op een switch via EVPN bekend gemaakt aan alle switches in het access netwerk. Ons netwerk heeft dus geen last meer van ARP en CAM timeouts. Veranderingen worden direct verspreid naar alle switches.
Door VXLAN en EVPN te combineren ontstaan er eigenlijk twee netwerken, de underlay en de overlay genoemd. De underlay verbindt de switches met elkaar en zorgt er voor dat ethernetframes in- en uitgepakt worden. De overlay is het netwerk wat hier overheen opgebouwd wordt. Dit is het netwerk waarin het verkeer van klanten gerouteerd wordt en wat voor de buitenwereld het zichtbare netwerk is.
VXLAN en EVPN zijn open standaarden. Dat maakt het mogelijk om in de toekomst ook gebruik te maken van apparatuur van andere merken en om ook andersoortige apparaten deel te laten nemen aan de set-up. Zo hebben we bijvoorbeeld al tests uitgevoerd om hypervisors via VXLAN te ontsluiten. Dat maakt het ontsluiten van virtuele machines en virtuele netwerken nog een stuk simpeler.
Nieuwe mogelijkheden met VXLAN en EVPN
Het gebruik van VXLAN en EVPN, en het in algemenere zin gebruik van software en hardware van Arista, biedt ons een aantal nieuwe mogelijkheden die voordelen voor onszelf en voor klanten van BIT. Hieronder zal ik een aantal daarvan opsommen.
Multi-Chassis Link Aggregation Group
Eén van de nieuwe mogelijkheden is de ondersteuning van Multi-Chassis Link Aggregation Group (MC-LAG). Hierbij worden meerdere verbindingen, uitkomend op verschillende switches, gebundeld tot één logische verbinding. Bij uitval van één van de switches uit de MC-LAG verlies je dan weliswaar capaciteit, maar de verbinding blijft wél werken.
Een beperking van MC-LAG is wel dat het alléén geïmplementeerd kan worden op vooraf gekozen paren van switches. We hebben er bij BIT voor gekozen om hierbij altijd paren te maken van twee switches die in dezelfde serverruimte staan. Uiteraard zijn procedures bij BIT zo ingericht dat er nooit tegelijkertijd werkzaamheden (zoals software updates of wijzigingen) uitgevoerd worden op switches die samen een paar vormen.
Om als klant gebruik te kunnen maken van MC-LAG, moet de switch waar de verbindingen naar BIT op uitkomen Link Aggregation Control Protocol (LACP) , port channeling of óók MC-LAG (in het geval de verbindingen aan de klantzijde ook op verschillende switches uitgekoppeld worden) ondersteunen.
Redundantie door gebruik van vARP
Het zojuist beschreven MC-LAG kan gebruikt worden om switches van klanten (of eventueel servers die port channeling ondersteunen) redundant aan te sluiten op een set switches van BIT. Veel klanten sluiten hun netwerk echter via een router of firewall aan. En het komt ook vaak voor dat een klant in verschillende serverruimtes apparatuur heeft staan, waardoor redundant aansluiten op een MC-LAG paar alleen mogelijk wordt door verbindingen naar een MC-LAG paar in één serverruimte te maken. Het bijkomende gevolg is dat ook apparatuur in een andere serverruimte afhankelijk wordt van de beschikbaarheid van de ruimte waar het MC-LAG paar staat. Dat komt de beschikbaarheid niet ten goede dus.
Gelukkig zijn er meer manieren om klanten redundant aan te sluiten. De manier die we daarom veruit het meest gebruiken, heet ‘vARP’ (Virtual Address Resolution Protocol). Hierbij wordt één uniek virtueel gateway IP-adres aangeboden op alle poorten van een klant. Die gateway is tegelijkertijd op al deze poorten actief. Iedere switch (of dan eigenlijk dus: router) van BIT wordt hiermee een gateway voor het klantennetwerk, wat ervoor zorgt dat routering optimaal is. Apparaten van de klant in dit IP-netwerk pakken altijd de gateway van de switch waar ze op aangesloten zijn. Het gebruik van vARP maakt het voor ons makkelijker om een klantennetwerk op verschillende plekken aan te sluiten op ons netwerk, waarbij het voor de klant gewoon één netwerk is waarin hij één gateway heeft en waarin zijn machines ook onderling gewoon kunnen communiceren. In de overlay lijkt het dus een simpel netwerk voor de klant, terwijl in de underlay met VXLAN, EVPN en vARP gezorgd wordt dat verkeer op de juiste poorten van de juiste switches in de spine/leaf set-up eindigt.
Automatisering
De software van Arista biedt veel mogelijkheden tot automatisering. Zo wordt Ansible ondersteund om configuraties mee te beheren en uit te rollen, en zijn er mogelijkheden om via een API te communiceren met switches. Met de libraries die Arista biedt is het simpel informatie uit switches te verzamelen. Dit gebruiken we onder andere om monitoring en troubleshooting van de switches mee te doen, maar ook kunnen we hiermee mogelijk maken dat klanten meer inzicht in de status van hun switchpoorten krijgen via de BIT Portal.
De volledige configuratie van alle switches wordt via Ansible beheerd. Ansible maakt het mogelijk om configuraties via playbooks, een soort recepten, te standaardiseren, waarbij per klant slechts een set aan de voor die klant specifieke configuratievariabelen, zoals op welke switchpoort van welke switch een klant aangesloten is, aangeleverd hoeft te worden. Dit voorkomt dat er fouten gemaakt worden bij het maken van configuraties. Via Ansible is het ook mogelijk om deze configuraties vervolgens uit te rollen naar switches.
De Ansible configuraties en gebruikte playbooks worden beheerd via Gitlab, een versiebeheerpakket. Dit maakt accountability (wie heeft wat wanneer gewijzigd) mogelijk. BIT hanteert hierbij een vier-ogen-principe voor wijzigingen, wat door Gitlab afgedwongen wordt. Ook maken we gebruik van "CI/CD pipelines" in Gitlab. Dit zijn scripts die voorgestelde wijzigingen op allerlei manieren controleren op eventuele fouten, vóórdat ze geaccepteerd en uitgerold kunnen worden.
Datavisualisatie door streaming telemetry
De nieuwe Arista switches ondersteunen streaming telemetry, waardoor we in vergelijking met het oude netwerk veel meer verschillende en vooral veel sneller meetwaarden beschikbaar hebben. Dat geeft een beter beeld van de status van het netwerk en kan bij problemen veel sneller en gedetailleerder inzicht geven.
In een recente blogpost heb ik al meer verteld over de tools en technieken die we gebruiken om de streaming telemetry data die de switches produceren toegankelijk te maken voor klanten via onze portal.
Meer weten over ons colocatienetwerk?
We zijn natuurlijk erg enthousiast over deze nieuwe set-up en delen graag onze kennis met je. Wil je meer weten, dan kun je contact opnemen via info@bit.nl of via 0318 648 688.
Door: Teun Vink